language-diversity
Evolution of Linguistic Diversity (In Development)
This project explores how words evolve to have multiple meanings over time and how people’s sensitivity to word variations affects the way word meanings change. We use word2vec embeddings, generate graph networks of words with high similarities and derive the coexistence of multiple word meanings (polysemy) using the local clustering coefficient. As a proxy for sensitivity to word variations, we use word concreteness ratings.
Note: The project is currently in development. Its present version includes the German language, covering the time period from the 1950s to the 1990s.
Datasets
Word2Vec Embeddings
- Historical HistWords: Word Embeddings for Historical Text [1]
- Contemporary NLPL word embeddings repository [2]
Concreteness Ratings
Get Started
To set up the project environment and install all necessary dependencies, please run the following command:
pip install -r requirements.txt
To download and preprocess the datasets, run main.py. The external data for German requires 3.9 GB.
python main.py -l german
To recreate the results, you can run the run.ipynb notebook.
Intermediary Results
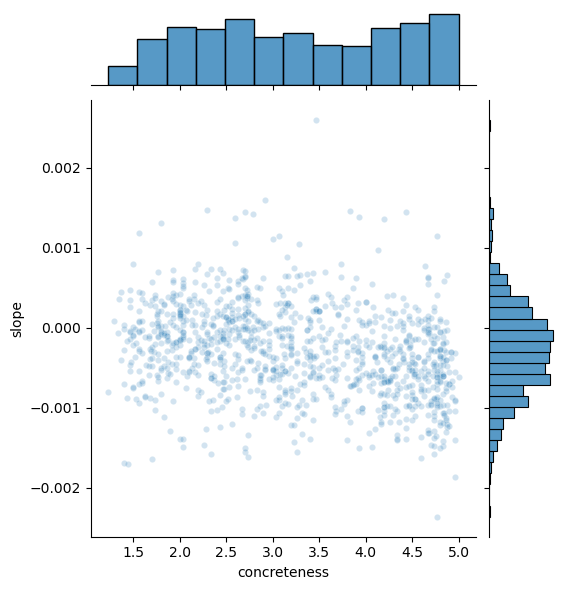
So far, we have identified a moderate positive correlation (0.4) between people’s sensitivity to word variations and an increase in polysemy. This correlation was determined by analyzing the Spearman Rank Correlation Coefficient of word concreteness ratings and the rate of change in word polysemy across decades, from the 1950s to the 1990s. The scatterplot below shows this relationship between those variables.
Upcoming
The next steps in this project are:
- Adding similar results for English and French
- Validate the results for German by using concreteness ratings from a different source
- Validating the polysemy scores and potentially adjusting the cosine similarity cutoff for generating the graph network
- Control our findings for word frequency